SQLAlchemy ORM性能测试
Flaskz封装了SQLAlchemy ORM以操作数据库,为了适配不同的使用场景,对性能进行了测试,重点测试了relationship的lazy属性对于性能的影响,以供大家参考。
因为使用的是个人电脑+VPN远程连接进行的测试,可能数据有所波动和差异。
测试环境
- 网络 - VPN远程连接到公司内网中的MySql
- 数据库 - MySql
- PC配置 - Macbook Pro / 2.6 GHz 6-Core Intel Core i7 / 16 GB 2667 MHz DDR4
测试数据
数据库结构&数据量
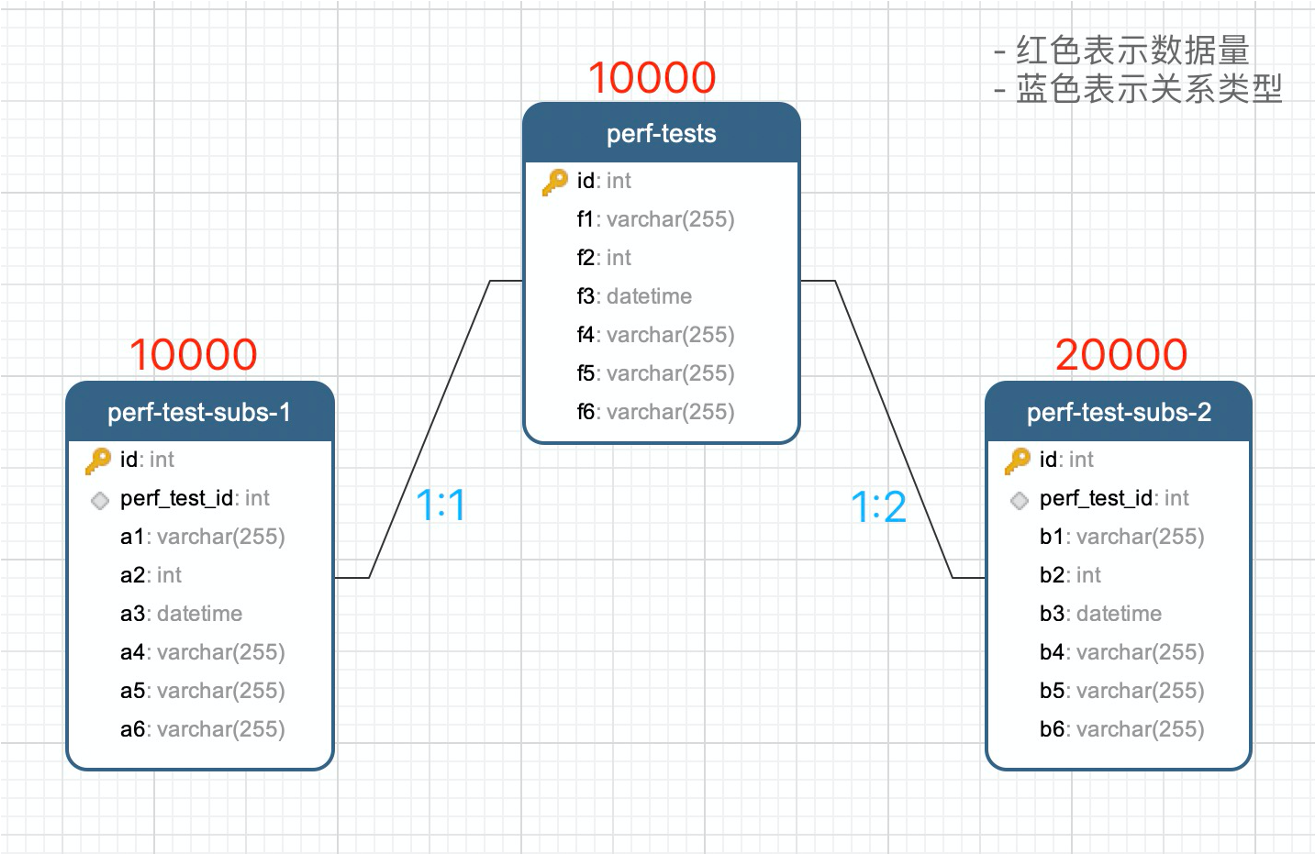
数据模型代码
from datetime import datetime
from flaskz.models import ModelBase, ModelMixin
from sqlalchemy import Column, Integer, String, DateTime, ForeignKey
from sqlalchemy.orm import relationship
class PerfTestModel(ModelBase, ModelMixin): # 主表
__tablename__ = 'perf-tests'
id = Column(Integer, primary_key=True, autoincrement=True) # primary key
f1 = Column(String(255))
f2 = Column(Integer)
f3 = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
f4 = Column(String(255))
f5 = Column(String(255))
f6 = Column(String(255))
subs1 = relationship('PerfTestSubModel1', uselist=False, cascade='all,delete-orphan', lazy='joined') # 1:1
subs2 = relationship('PerfTestSubModel2', cascade='all,delete-orphan', lazy='joined') # 1:N
class PerfTestSubModel1(ModelBase, ModelMixin): # 从表1
__tablename__ = 'perf-test-subs-1'
id = Column(Integer, primary_key=True, autoincrement=True) # primary key
perf_test_id = Column(Integer, ForeignKey('perf-tests.id', ondelete='CASCADE'), nullable=False) # 外键
a1 = Column(String(255))
a2 = Column(Integer)
a3 = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
a4 = Column(String(255))
a5 = Column(String(255))
a6 = Column(String(255))
class PerfTestSubModel2(ModelBase, ModelMixin): # 从表2
__tablename__ = 'perf-test-subs-2'
id = Column(Integer, primary_key=True, autoincrement=True) # primary key
perf_test_id = Column(Integer, ForeignKey('perf-tests.id', ondelete='CASCADE'), nullable=False) # 外键
b1 = Column(String(255))
b2 = Column(Integer)
b3 = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
b4 = Column(String(255))
b5 = Column(String(255))
b6 = Column(String(255))
测试结果
| 操作 | 结果包含relationship | lazy=joined | 查询时间 | 总时间(查询+to_dict) | 备注 |
|---|---|---|---|---|---|
| 全量查询 | 是 | 是 | 6秒 | 8.7秒 | 一次连接查询 |
| 是 | 否 | 1秒 | 8分13秒 | to_dict时循环20000次查询relationship | |
| 否 | 是 | 6秒 | 7.6秒 | 一次连接查询 | |
| 否 | 否 | 2.7秒 | 4.3秒 | 一次查询 | |
| 条件查询 (搜索/过滤/排序) (返回100条数据) |
是 | 是 | 0.18秒 | 0.19秒 | |
| 是 | 否 | 0.15秒 | 6秒 | to_dict时循环查询relationship,循环次数=数量*2 | |
| 否 | 是 | 0.19秒 | 0.20秒 | ||
| 否 | 否 | 0.11秒 | 0.12秒 | ||
| 批量添加 | 是 | - | - | 15分 | 循环执行了40000次插入 |
| 否 | - | - | 1.7秒 | 一次插入 | |
| 批量删除 | - | - | - | 0.6秒 |
测试总结
- lazy = joined连接查询会导致查询时间变长
- 如果输出结果需要relationship数据,会大大减少查询次数
- 如果输出结果不需要relationship数据,会有性能损耗浪费
- 如果不清楚是否需要relationship数据或只是偶尔需要,请不要设置lazy=joined,否则可能因为连接查询带来性能损耗
- 如果结果需要relationship数据,设置lazy=joined可以提高性能,请注意, 如果没有lazy=joined可能会因为循环查询relationship数据导致严重的性能问题
- lazy != joined但是结果中又需要relationship数据时,可以通过先全部加载,然后append的方式进行,性能和lazy=joined的方式基本相同
- 如果总数据量/分页数据量较少时,lazy=joined对性能影响不大,但是可以大大减少代码和逻辑
- 如果添加数据量较大,不建议通过relationship级连插入,非常的慢,可以考虑分类批量插入的方式
外连接查询
如果没有设置relationship或者relationship的lazy属性是noload,但是输出结果中又希望包含关联表的信息,可以考虑使用外连接的查询方式。
将数据读取出来以后,再对结果进行拼接的方式,示例如下
session = get_db_session()
query = session.query(PerfTestModel, PerfTestSubModel1, PerfTestSubModel2)
query = query.outerjoin(PerfTestSubModel1).outerjoin(PerfTestSubModel2) # 外连接查询
id_map = {}
for item in query.all(): # 每条结果数据是包含三个数据模型对象的元组
model = item[0]
id = model.id
model_value = id_map.get(id)
if model_value is None: # 数据拼接
model_value = id_map[id] = model.to_dict()
model_value['subs1'] = item[1].to_dict()
model_value['subs2'] = []
result.append(model_value)
model_value.get('subs2').append(item[2].to_dict())
print(result)