Flaskz介绍2--数据模型扩展类
Flaskz提供了BaseModelMixin和ModelMixin两个数据库模型扩展类,封装了常用的增删改查等方法,并添加了数据校验,批量操作等功能。
将分散在函数中的业务逻辑和数据处理抽象到模型类层级集中处理,提高系统的整体性和模块化, 也将开发人员从琐碎的数据库操作中解放出来,从而可以更加专注于业务功能的实现。
本文不涉及数据库表的迁移操作,感兴趣的可以参考Alembic。
BaseModelMixin
BaseModelMixin类主要是封装了数据库的增删改查基本操作。
增加数据
- add_db(data)
- 功能:将dict对象(json数据)插入到模型对应的数据库表中
添加过程中会对数据进行处理,对不需要录入的字段(数据库自动生成)进行过滤
同时也会对包含在data中的关系数据进行级联插入
class User(ModelMixin): id = Column(Integer, primary_key=True, autoincrement=True) # 自增主键 name = Column(String(32), unique=True, nullable=False) # name不能重复 age = Column(Integer) addresses = relationship(Address, cascade='all,delete,delete-orphan', lazy='joined') # Address关系映射 #... updated_at = Column(DateTime(), default=datetime.now, onupdate=datetime.now) # 数据更新时间,系统自动维护 # auto_columns列表中的属性,即使在传递过来的数据中存在,也会在添加/编辑时被过滤掉,列元素可以是列名字也可以是列对象。 like_columns = ['name', description] # 可以进行模糊查询的属性列表,参考query_pss auto_columns = ['id', updated_at] # 系统自动生成&维护,增加/编辑时不会受传递的参数影响 - 参数:
- {dict}data --要添加的dict对象
- 返回:添加成功的模型类instance对象
- 示例:
User.add_db({ "name":"taozh", "age":18, "id":"10", # id属性会被过滤掉,数据库自动生成 "updated_at":"Tue, 10 Sep 2021 12:01:27 GMT" # updated_at属性会被过滤掉,系统自动生成 })
- 功能:将dict对象(json数据)插入到模型对应的数据库表中
- check_add_data(data)
- 功能:对于要添加的数据进行校验,默认对数据的唯一性进行了校验,可以重载以增加自定义校验,例如)数据完整性/数据格式等。
- 参数:
- {dict}data --要添加的dict数据
- 返回:True或者校验失败原因,如果不是True则表示校验失败,并直接返回,如果数据唯一性校验发现数据已存在,则返回res_status_codes.db_data_already_exist
- 示例:
user1 = {"name":"taozh","age":18} User.check_add_data(user1) # True User.add_db(user1) User.check_add_data(user1) # res_status_codes.db_data_already_exist
- bulk_add(items, with_relationship=False)
- 功能:一次性添加多条记录
- 参数:
- {list}items --要添加的多条数据列表
- {boolean}with_relationship --是否需要添加关联关系,默认为False
-如果为True,则会添加关联关系,比如user的addresses
-如果为False,则会忽略关联关系,此种方式效率更高,但是没有类似add_db的属性过滤功能
- 示例:
User.bulk_add([ {"name":"user1","age":11}, {"name":"user2","age":12}, {"name":"user3","age":13}])
删除数据
- delete_db(pk_value)
- 功能:根据主键删除对应的数据
- 参数:
- pk_value --要删除数据的主键值,比如id,name等
- 返回:删除的模型类instance对象
- 示例:
ins = User.delete_db(10) # 将id为10的User记录删除
- delete_by(by_dict)
- 功能:删除符合指定条件的数据
- 参数:
- {dict}by_dict --指定的属性集合,符合条件的数据会被删除
- 返回:删除数据的数量
- 示例:
delete_count = SysActionLog.delete_by({'type': 'login'}) # 删除所有type为login的操作日志
- delete_by_query(query_options, no_criterion_allowed=False)
- 功能:删除符合指定查询条件的数据
- 参数:
- {dict}query_options --指定的查询条件,符合条件的数据会被删除
- {boolean}no_criterion_allowed --如果没有指定query_options查询条件,
- 如果no_criterion_allowed=True,删除全部数据
- 如果no_criterion_allowed=False,不做删除,返回0
- 返回:删除数据的数量
- 示例:
# 删除2023-01-01之前type为login的操作日志 delete_count = SysActionLog.delete_by_query({ 'type':'login', 'created_at': { '<': '2023-01-01 00:00:00' }})
- check_delete_data(pk_value)
- 功能:对于要删除的主键值进行校验,默认检查主键值对应的记录是否存在
- 参数:
- pk_value --要删除数据的主键值,比如id,name等
- 返回:True或者校验失败原因,如果不是True则表示校验失败,并直接返回,如果主键值对应的记录在数据库表中不存在,则返回res_status_codes.db_data_not_found
- 示例:
user = User.add_db({"name":"taozh","age":18}) # user.id=123 User.check_delete_data(123) # True User.check_delete_data(-123) # res_status_codes.db_data_not_found
- bulk_delete(items)
- 功能:一次性删除多条记录,会对items列表进行遍历查询,然后逐个删除
- 参数:
- {list}items -- 要删除的记录属性集/主键值列表
- 示例:
User.bulk_delete([ 10,20, # 通过主键值进行删除 {"name":"user2"}, # 通过属性集进行删除 {"name":"user3"}])
- clear_db()
- 功能:清空模型的所有数据
- 返回:
- {int}count --清空的数据总数
- 示例:
User.clear_db()
修改数据
- update_db(data)
- 功能:根据dict对象(json数据)中的主键从数据库查找对应的记录,并进行更新,同时也会对data中包含的关系属性进行更新或替换
请注意这里采用的是局部更新而非替换,只有data中包含的属性才会进行更新,如果不包含则保留原值
更新过程中会对数据进行处理,对不需要录入的字段(数据库自动生成/auto_columns)进行过滤
- 参数:
- {dict}data --要修改的数据,必须带有主键值
- 返回:更新成功的模型类instance对象,如果没有找到记录,则返回None
- 示例:
User.update_db({ "id":"10", # 根据id查找到对应的user记录 "age":19, # 只更新了age属性,name属性保持不变 "updated_at":"Tue, 10 Sep 2021 12:01:27 GMT" # updated_at属性会被过滤掉,系统自动生成 })
- 功能:根据dict对象(json数据)中的主键从数据库查找对应的记录,并进行更新,同时也会对data中包含的关系属性进行更新或替换
- check_update_data(data)
- 功能:对于要修改的数据进行校验,默认会对数据是否存在以及属性的唯一性进行校验,可以重载以增加自定义校验,例如)数据完整性/数据格式等。
- 参数:
- {dict}data --要修改的数据
- 返回:True或者校验失败原因,如果不是True则表示校验失败,并直接返回
如果要修改的数据不存在,则返回res_status_codes.db_data_not_found
如果数据唯一性校验发现除当前数据以外的数据已存在,则返回res_status_codes.db_data_already_exist
- 示例:
user1 = User.add_db({"name":"user1","age":18}) # user1.id = 10 user2 = User.add_db({"name":"user2","age":18}) # user2.id = 11 User.check_update_data({"id":10,"age":19}) # True User.check_update_data({"id":10,"name":"user1","age":19}) # True,虽然id为10的记录name为user1,但是因为修改的是当前数据,所以唯一性校验成功 User.check_update_data({"id":10,"name":"user2","age":19}) # res_status_codes.db_data_already_exist,name为user2的记录已经存在且不是当前数据,唯一性校验失败 User.check_update_data({"id":100,"age":19}) # res_status_codes.db_data_not_found,数据不存在
- bulk_update(items, with_relationship=False)
- 功能:一次性更新多条记录
- 参数:
- {list}items --要更新的多条数据列表
- {boolean}with_relationship --是否需要更新关联关系数据,默认为False
-如果为True,则会更新关联关系数据,比如替换user的addresses
-如果为False,则会忽略关联关系,此种方式效率更高,但是没有类似update_db的属性过滤功能
- 示例:
User.bulk_update([ {"id":11,"age":12}, {"id":12,"age":13}, {"id":13,"age":14}])
to_dict(option=None) 查询数据
- query_all()
- 功能:查询当前模型类的所有记录对象,并以列表的形式返回
- 返回:包含所有记录对象的列表
- 示例:
User.query_all()
- query_by(by_dict, return_first=False)
- 功能:根据属性条件查询符合条件的记录对象,根据return_first参数不同,返回的值可能不同(对象/列表)
- 参数:
- {dict}by_dict --查询条件的属性集合
- {boolean}return_first -- 是否返回符合条件的第一个对象,默认是False,即返回列表
-如果为True,返回符合条件的第一个对象
-如果为False,返回符合条件的数据列表
- 返回:符合条件的对象列表或第一个对象
- 示例:
User.query_by({"age":18}) # 查询所有age=18的user记录 User.query_by({"name":"user1"},True) # 查询name=user1的第一条记录
- query_by_pk(pk_value)
- 功能:根据主键值查询符合条件的记录对象
- 参数:
- pk_value --要查询记录的主键值
- 返回:主键值对应的记录对象
- 示例:
User.query_by_pk(10) # 查询主键id=10的user记录
- query_pss(pss_option)
- 功能:pss=page+search+sort,根据分页/排序/搜索/等条件查询符合条件的记录列表,这是功能最强大的一个查询函数,可以实现各种查询功能
- 参数:
- {dict}pss_option --分页排序搜索等查询条件,
建议先通过 parse_pss 方法将查询参数转换再调用query_pss方法,有如下可选项
- order --查询结果集的排序方式,支持多列排序,如果不指定,默认使用get_query_default_order的order(默认是主键对应的列)
- limit --查询结果集的限制条数,即每次返回的最多记录数,只有>0才会起作用
- offset --查询结果集的偏移起始值,即跳过多少条记录,只有>0才会起作用
- filter_likes -- 通过OR/AND连接的多个查询条件集合,用于模糊查询(包含&不包含),只有查询payload或模型类中指定的like_columns中的列/属性才会进行模糊查询
- filter_ands -- 通过AND进行连接的多个查询条件集合
- filter_ors -- 通过OR进行连接的多个查询条件集合
- group -- 查询分组
- relationships -- relationship相关的查询条件集合
- {dict}pss_option --分页排序搜索等查询条件,
建议先通过 parse_pss 方法将查询参数转换再调用query_pss方法,有如下可选项
- 返回:符合条件的对象列表
- 示例:
result, result = TemplateModel.query_pss(parse_pss( TemplateModel, { # FROM templates "search": { # 条件查询 "like": "t", # -模糊查询: name like '%t%' OR description like '%t%' (TemplateModel.like_columns = ['name', description]) "age": { # -范围查询: AND (age>1 AND age<20) ">": 1, # operator:value, operators)'='/'>'/'<'/'>='/'<='/'BETWEEN'/'LIKE'/'IN' "<": 20 }, "email": "taozh@focus-ui.com", # -精确查询: AND (email='taozh@focus-ui.com') # "address.city": "New York", # -relation字段精确查询 "_ors": { # -通过OR进行连接的多个查询条件集合: AND (country='America' OR country='Canada') "country": "America||Canada" }, "_ands": { # -通过AND进行连接的多个查询条件集合: AND (grade>1 AND grade<5) "grade": { ">": 1, "<": 5 } } }, "sort": { # 查询结果集的排序方式: ORDER BY templates.name ASC "field": "name", # -排序属性 "order": "asc" # -排序方式: asc/desc }, # "sort":[ # 多列排序: ORDER BY templates.name ASC, templates.age DESC # {"field": "name", "order": "asc"}, # {field": "address.city", "order": "desc"} # -relation字段排序 # ], "page": { # 分页: LIMIT ? OFFSET ? (20, 0) "offset": 0, # -偏移为0 "size": 20 # -每页20条记录 }, "group": "email" # 分组: GROUP BY templates.email })) #以上查询条件通过parse_pss方法转换以后,等价下列查询条件 TemplateModel.query_pss({ "filter_likes": ["name like '%t%'", "description like '%t%'"], "filter_ands": ["email='taozh@focus-ui.com'", "age>1", "age<20", "grade>1", "grade<5"], "filter_ors": ["country='America'", "country='Canada'"], "offset": 0, "limit": 20, "order": [asc(TemplateModel.name)] # [asc(TemplateModel.name), desc(TemplateModel.age)], "group": [TemplateModel.email] })
- get_query_default_order()
- 功能:返回查询时默认使用的排序方式,默认使用系统的主键进行排序,可重写以自定义默认排序
- 返回:默认的排序方式
- 示例:
class Log: #... updated_at = Column(DateTime(), default=datetime.now, onupdate=datetime.now) def get_query_default_order(cls): return desc(cls.updated_at) # 使用更新时间的倒序作为查询时默认的排序方式
- count(search=None)
- 功能:查询当前模型类的记录数,如果指定了search则返回符合条件的记录数,如果search为None则返回记录总数
- 返回:
- {int}count --记录数(全量/条件)
- 版本:>= v1.6
- 示例:
SysActionLog.count() # 总数 SysActionLog.count(parse_pss( # 符合条件的记录数 TemplateModel, { # FROM templates "search": { # WHERE "like": "t", # name like '%t%' OR description like '%t%' (TemplateModel.like_columns = ['name', description]) "age": { # AND (age>1 AND age<20) ">": 1, # operator:value, operators)'='/'>'/'<'/'>='/'<='/'BETWEEN'/'LIKE'/'IN' "<": 20 }, "email": "taozh@focus-ui.com", # AND (email='taozh@focus-ui.com') "_ors": { # AND (country='America' OR country='Canada') "country": "America||Canada" }, "_ands": { # AND (grade>1 AND grade<5) "grade": { ">": 1, "<": 5 } } } }))
数据序列化
- to_dict(option=None)
- 功能:将模型对象转换为包含属性的字典,除了对象的自身属性,也可以通过选项控制级联对象的输出
- 参数:
- {dict|None}option --转换选项,可以设置cascade/include/exclude等选项,请参考ins_to_dict方法
默认通过to_dict_field_filter回调函数对属性进行控制,如果设置了include/exclude,to_dict_field_filter将不起作用
- {dict|None}option --转换选项,可以设置cascade/include/exclude等选项,请参考ins_to_dict方法
- 返回:包含对象属性的字典
- 示例:
User.to_dict({ "cascade":1 # 会将第一级关系对象输出为字典的属性,比如addresses关系列表,就会以addresses:[{...},{...}]的格式输出到字典中 "exclude": ["password", "last_login_at"], # exclude中的字段不会返回,一般不直接设置,而是通过重写to_dict_field_filter方法进行属性过滤 "addresses":{ # 也可以对于级联对象的输出进行设置 "include": ["id","city"], # 只有include中的字段才会返回,include的优先级>exclude,,一般不直接设置,而是通过重写to_dict_field_filter方法进行属性过滤 } })
- to_dict_field_filter(field)
- 功能:用于模型对象转换为字典对象时,对属性是否转换进行控制,一般用于重写定制化,见示例代码
- 参数:
- {string}filed --待检测的field属性,比如id/name/age等
- 返回:
- -True,则field会被输出到字典中
- -False,则field不会输出到字典中
- 示例:
class User(ModelBase, ModelMixin): #... @classmethod def to_dict_field_filter(cls, field): return field not in ['password', 'last_login_at'] and super().to_dict_field_filter(field) # password/last_login_at属性不会输出到字典中
其它
- get_columns()
- 功能:返回模型类所有列的列表
- 返回:所有列组成的列表
- 示例:
for col in cls.get_columns(): field = cls.get_column_field(col) # col.key
- get_column_field(col)
- 功能:返回指定列的key属性(对应数据库中表的列名),如果通过info进行了设置,则返回info中的field属性
- 参数:
- {Column}col --指定的列对象
- 返回:列的key/field--数据库表的列名
- 示例:
name = Column(String(32), unique=True, nullable=False) # 返回"name" system_default = Column('default', Boolean, default=False, info={'field': 'system_default'}) # 返回"system_default",当列名和表名不一致时使用
- get_primary_column()
- 功能:获取模型类的主键列
- 返回:模型类的主键列
- 示例:
User.get_primary_column() # id列对象
- like_columns
- 功能:定义可以进行全局模糊查询的列,在BaseModelMixin.query_pss方法中使用
- 示例:
class User: id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32), unique=True, nullable=False) description = Column(String(255)) #... like_columns = ['name', description] # 可以进行模糊查询的属性列表,可以是字符串也可以是列对象
- auto_columns
- 功能:定义系统自动生成的属性列表,在添加/修改数据时使用,在auto_columns定义的属性会忽略data中的属性,而是系统自动生成
也可以通过列的info属性进行等价设置,见示例created_at列,不过还是建议通过auto_columns进行统一设置
- 示例:
class User: id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(32), unique=True, nullable=False) created_at = Column(DateTime(), default=datetime.now, info={'auto': True}) # created_at列的值,也会忽略data中的属性,系统自动生成 updated_at = Column(DateTime(), default=datetime.now, onupdate=datetime.now) #... auto_columns = ['id', updated_at] # 自动生成的列,增加/编辑时会忽略data中的属性
- 功能:定义系统自动生成的属性列表,在添加/修改数据时使用,在auto_columns定义的属性会忽略data中的属性,而是系统自动生成
- cast_type
- 功能:定义列在排序/过滤时的转换类型,默认不转换,如果设置了cast_type(类型/函数),会在SQL中添加CAST转换语句
一般用于列类型跟排序方式不一致的情况,例如)设置都是数字的字符列使用数字的方式进行排序
- 版本:>=1.8.3
- 示例:
class RoutingNeighbor: id = Column(Integer, primary_key=True, autoincrement=True) neighbor = Column(String(255), info={'cast_type': lambda col: cast(func.INET_ATON(col), BigInteger)}) # 对ip地址进行排序(mysql) as_number = Column(String(100), info={'cast_type': BigInteger}) # 以数字的方式对字符串列进行排序
- 功能:定义列在排序/过滤时的转换类型,默认不转换,如果设置了cast_type(类型/函数),会在SQL中添加CAST转换语句
ModelMixin
ModelMixin继承自BaseModelMixin,在其基础上增加了流程控制和逻辑校验,主要用于业务流程的定制和扩展,并针对API请求等场景进行了相关的封装,以便于模型数据和路由处理函数的对接。
大多数业务模型类都建议继承ModelMixin,尤其是要跟路由处理函数进行交互的模型类。
增加数据
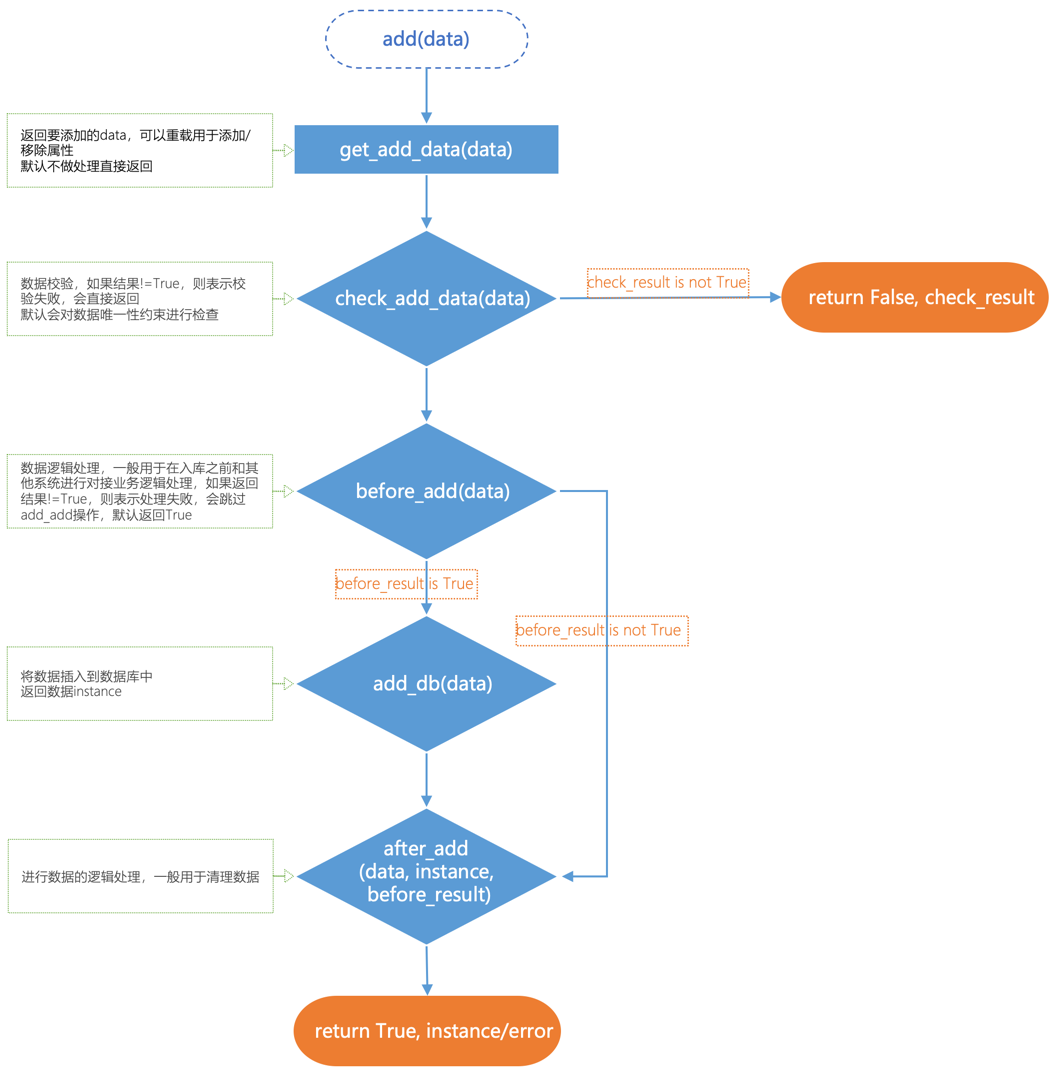
- add(data)
- 功能:将dict数据插入到模型对应的数据库表中,
在BaseModelMixin的add_db方法基础上添加了get_add_data/check_add_data/before_add/after_add等函数回调,并对异常进行了try/catch处理
各个函数的调用过程如下:
- get_add_data:调用get_add_data函数返回要添加的data,可以重载用于添加/移除属性,默认不做处理直接返回传入的data
- check_add_data:调用check_add_data函数进行数据校验,如果结果!=True,则表示校验失败,会直接返回,默认会对数据唯一性约束进行检查,参考BaseModelMixin.check_add_data方法
- before_add:调用before_add函数进行数据逻辑处理,一般用于在入库之前和其他系统进行对接和业务逻辑处理,如果返回结果!=True,则表示添加失败,会直接返回,默认返回True
- add_db:调用add_db函数,将数据插入到数据库表中,参考BaseModelMixin.add_db方法
- after_add:调用after_add函数进行数据的逻辑处理,一般用于清理数据。例如,用于角色管理中确保只有一个是默认值
- 参数:
- {dict}data --要添加的dict数据
- 返回:一个带有成功失败标志和结果的元组,可以通过标志进行逻辑判断
- -(True,instance),添加成功,返回True和添加成功的instance对象组成的元组
- -(False,fail_reason),添加失败,返回False和失败原因组成的元组,失败原因参考调用过程
- 示例:
User.add({ "name":"taozh", "age":18 })
- 功能:将dict数据插入到模型对应的数据库表中,
在BaseModelMixin的add_db方法基础上添加了get_add_data/check_add_data/before_add/after_add等函数回调,并对异常进行了try/catch处理
- get_add_data(data)
- 功能:对于要添加的数据进行处理,一般用于重载以附加属性/移除属性,请参考ModelMixin.add方法
- 参数:
- {dict}data --要添加的dict数据
- 返回:处理以后的dict数据,默认不做处理直接返回
- before_add(data)
- 功能:在将数据添加到数据库之前进行逻辑处理,比如和其他系统进行对接,一般用于重载以添加业务逻辑,请参考ModelMixin.add方法
- 参数:
- {dict}data --要添加的dict数据
- 返回:
- -True,表示处理成功或者不需要处理
- -False,表示处理失败
- 示例:
class NSOModelMixin: #... """ 操作DB之前,先调用NSO -NSO操作成功,操作数据库 -NSO操作失败,直接返回到客户端 """ @classmethod def before_add(cls, data): return cls.nso_add(data) # 调用NSO进行配置下发 @classmethod def nso_add(cls, data): nm = cls.get_nso_model() if nm: nso_data = cls.get_nso_data(data, 'add') if nso_data is None: return status_codes.nso_request_params_err result = nm.add(nso_data) if result[0] is False: # 添加失败 return result[1] # 返回失败原因 return True # 添加成功,返回True
- after_add(data, instance, before_result)
- 功能:无论添加成功还是失败都会调用,可以重载after_add,进行一些清理工作
- 参数:
- {dict}data:要添加的dict数据
- {BaseModelMixin}instance:添加成功的instance对象,如果失败可能是空
- {*}before_result:调用before_add的结果,一般用于处理调用before_add成功,但是插入数据库失败的场景
删除数据
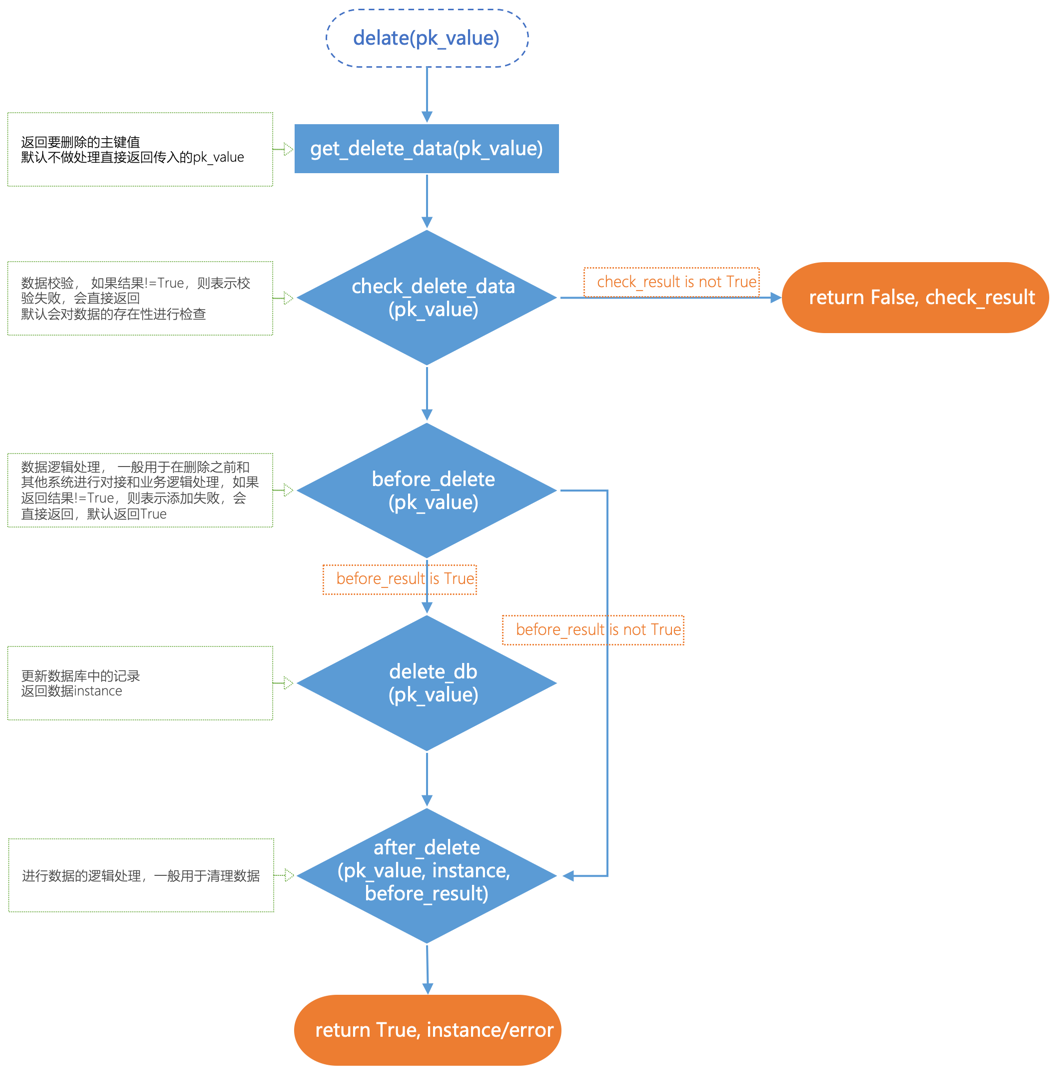
- delete(pk_value)
- 功能:根据主键删除对应的数据,
在BaseModelMixin的delete_db方法基础上添加了get_delete_data/check_delete_data/before_delete/after_delete等函数回调,并对异常进行了try/catch处理
各个函数的调用过程如下:
- get_delete_data:调用get_delete_data函数返回要删除的主键值,默认不做处理直接返回传入的pk_value
- check_delete_data:调用check_delete_data函数进行数据校验,如果结果!=True,则表示校验失败,会直接返回,默认会对数据的存在性进行检查,参考BaseModelMixin.check_delete_data方法
- before_delete:调用before_delete函数进行数据逻辑处理,一般用于在删除之前和其他系统进行对接和业务逻辑处理,如果返回结果!=True,则表示添加失败,会直接返回,默认返回True
- delete_db:调用delete_db函数,将数据从数据库中删除,参考BaseModelMixin.delete_db方法
- after_delete:调用after_delete函数进行数据的逻辑处理,一般用于清理数据。
- 参数:
- pk_value --要删除的主键值
- 返回:一个带有成功失败标志和结果的元组,可以通过标志进行逻辑判断
- -(True,instance),删除成功,返回True和删除成功的instance对象组成的元组
- -(False,fail_reason),删除失败,返回False和失败原因组成的元组,失败原因参考调用过程
- 示例:
User.delete(10)
- 功能:根据主键删除对应的数据,
在BaseModelMixin的delete_db方法基础上添加了get_delete_data/check_delete_data/before_delete/after_delete等函数回调,并对异常进行了try/catch处理
- get_delete_data(pk_value)
- 功能:返回待删除的主键值
- 参数:
- pk_value --要删除的主键值
- 返回:待删除的主键值,默认不做处理直接返回
- before_delete(pk_value)
- 功能:在将数据从数据库删除之前进行逻辑处理,比如和其他系统进行对接,一般用于重载以删除对应的业务逻辑,请参考ModelMixin.delete方法
- 参数:
- pk_value --要删除的主键值
- 返回:
- -True,表示处理成功或者不需要处理
- -False,表示处理失败
- 示例:
class NSOModelMixin: """ 操作DB之前,先调用NSO -NSO操作成功,操作数据库 -NSO操作失败,直接返回到客户端 """ #... @classmethod def before_delete(cls, pk_value): return cls.nso_delete(pk_value) # 调用NSO删除对应的配置 @classmethod def nso_delete(cls, pk_value): """ 一般NSO删除都是通过name进行操作 :param pk_value: :return: """ nm = cls.get_nso_model() if nm: delete_data = cls.get_nso_delete_data(pk_value) if delete_data is None: return res_status_codes.db_data_not_found result = nm.delete(delete_data) if result[0] is False: # 删除失败 return result[1] # 返回失败原因 return True # 删除成功,返回True
- after_delete(pk_value, instance, before_result)
- 功能:无论删除成功还是失败都会调用,可以重载after_after_delete,进行一些清理工作
- 参数:
- pk_value:要删除对象的主键值
- instance:删除成功的instance对象,如果失败可能是空
- before_result:调用before_delete的结果,一般用于处理调用before_delete成功,但是删除数据库失败的场景
修改数据
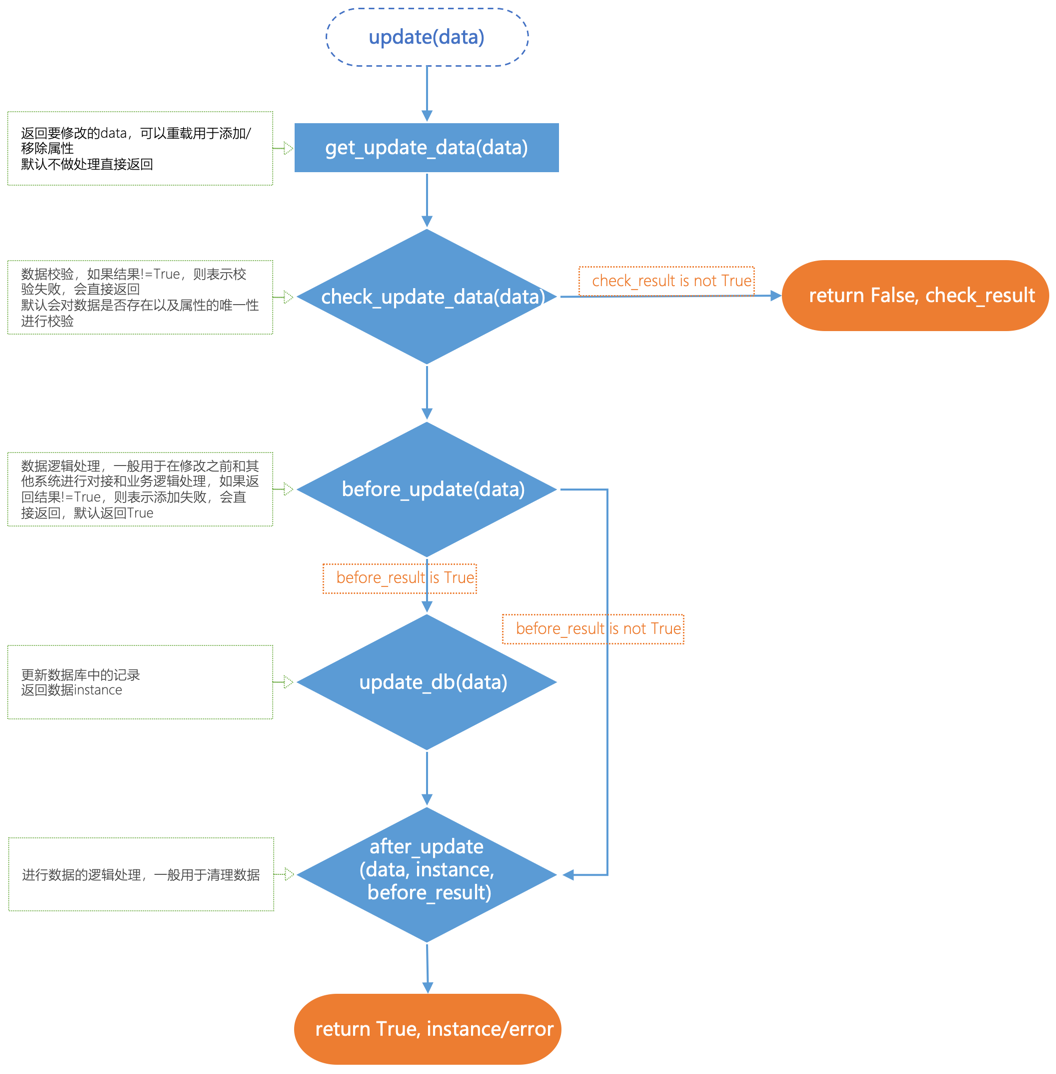
- update(data)
- 功能:根据dict对象(json数据)中的主键从数据库查找对应的记录,并进行更新,
在BaseModelMixin的update_db方法基础上添加了get_update_data/check_update_data/before_update/after_update等函数回调,并对异常进行了try/catch处理
各个函数的调用过程如下:
- get_update_data:调用get_update_data函数返回要修改的data,可以重载用于添加/移除属性,默认不做处理直接返回传入的data
- check_update_data:调用check_update_data函数进行数据校验,如果结果!=True,则表示校验失败,会直接返回,默认会对数据是否存在以及属性的唯一性进行校验,参考BaseModelMixin.check_update_data方法
- before_update:调用before_update函数进行数据逻辑处理,一般用于在修改之前和其他系统进行对接和业务逻辑处理,如果返回结果!=True,则表示添加失败,会直接返回,默认返回True
- update_db:调用add_db函数,更新数据库中的记录,参考BaseModelMixin.update_db方法
- after_update:调用after_update函数进行数据的逻辑处理,一般用于清理数据。
- 参数:
- {data}data --要修改的dict数据,必须带有主键值
- 返回:一个带有成功失败标志和结果的元组,可以通过标志进行逻辑判断
- -(True,instance),修改成功,返回True和修改成功的instance对象组成的元组
- -(False,fail_reason),修改失败,返回False和失败原因组成的元组,失败原因参考调用过程
- 示例:
User.update({ "id":10 "name":"taozh", "age":19 })
- 功能:根据dict对象(json数据)中的主键从数据库查找对应的记录,并进行更新,
在BaseModelMixin的update_db方法基础上添加了get_update_data/check_update_data/before_update/after_update等函数回调,并对异常进行了try/catch处理
- get_update_data(data)
- 功能:对于要修改的数据进行逻辑处理,一般用于重载以附加属性/移除属性,请参考ModelMixin.update方法
- 参数:
- {data}data --要修改的dict数据
- 返回:处理以后的dict数据,默认不做处理直接返回
- before_update(data)
- 功能:更新数据库之前进行逻辑处理,比如和其他系统进行对接,一般用于重载以添加业务逻辑,请参考ModelMixin.update方法
- 参数:
- {data}data --要修改的dict数据
- 返回:
- -True,表示处理成功或者不需要处理
- -False,表示处理失败
- 示例:
class NSOModelMixin: """ 操作DB之前,先调用NSO -NSO操作成功,操作数据库 -NSO操作失败,直接返回到客户端 """ @classmethod def before_update(cls, data): return cls.nso_update(data) # 调用NSO更新设备上的配置 @classmethod def nso_update(cls, data): nm = cls.get_nso_model() if nm: nso_data = cls.get_nso_data(data, 'update') if nso_data is None: return status_codes.nso_request_params_err result = nm.update(nso_data) if result[0] is False: # 更新失败 return result[1] # 返回失败原因 return True # 更新成功,返回True
- after_update(data, instance, before_result)
- 功能:无论修改成功还是失败都会调用,可以重载after_update,进行一些清理工作
- 参数:
- data:要修改的数据
- instance:修改成功的instance对象,如果失败可能是空
- before_result:调用before_update的结果,一般用于处理调用before_update成功,但是修改数据库失败的场景
查询数据
- query_all()
- 功能:在BaseModelMixin的query_all基础上,添加了try/catch异常处理
- 返回:一个带有成功失败标志和结果的元组,这也是和BaseModelMixin.query_all函数的主要区别,BaseModelMixin.query_all返回的是结果列表
- -(True,instance_list),查询成功,返回True和包含所有记录对象的列表组成的元组
- -(False,fail_reason),查询失败,返回False和失败原因组成的元组
- 示例:
class User(ModelBase, ModelMixin) # 继承自ModelMixin pass User.query_all() #返回的是元组 class Address(ModelBase, BaseModelMixin) # 继承自BaseModelMixin pass Address.query_all() #返回的是结果列表
- query_pss(pss_option)
- 功能:在BaseModelMixin的query_pss基础上,添加了try/catch异常处理,请参考BaseModelMixin.query_pss方法
- 返回:一个带有成功失败标志和结果的元组,这也是和BaseModelMixin.query_pss函数的主要区别,BaseModelMixin.query_pss返回的是结果列表
- -(True,instance_list),查询成功,返回True和包含所有记录对象的列表组成的元组
- -(False,fail_reason),查询失败,返回False和失败原因组成的元组
- 示例:
class User(ModelBase, ModelMixin) # 继承自ModelMixin pass User.query_pss({...}) #返回的是元组 class Address(ModelBase, BaseModelMixin) # 继承自BaseModelMixin pass Address.query_pss({...}) #返回的是结果列表